闲来无事,搞个词云玩玩,此功能用来数据分析的居多,请各位自行食用~
首先要安装了python的环境,将环境变量配置好,然后再安装pip,我这里因为没有识别pip,所以选择的是手动安装配置
使用pip –version(python2版本)或者pip3 –version(python3以上版本)查看是否安装好
我的pip位置是:
C:\Users\Administrator\AppData\Local\Programs\Python\Python310\Lib\site-packages\pip
在这个位置,添加一个pip.ini,内容如下:
[global] index-url = https://mirrors.aliyun.com/pypi/simple/ timeout = 1000 trusted-host = mirrors.aliyun.com
安装完之后开始下载项目,项目地址:https://github.com/amueller/word_cloud
pip install wordcloud
wordcloud默认是为了英文文本来做词云的,如果需要制作中文文本词云,就需要先对中文进行分词。这里就需要用到中文分词库「jieba」。
「jieba」是优秀的中文分词库,需要安装。它的原理是利用一个中文词库,确定中文字符之间的关联概率,汉字间概率大的组成词组,形成分词结果,除了分词,还可以添加自定义词组。
pip install jieba
这里使用jieba.lcut(s),返回列表型分词结果,s是形参,不是固定参数
新建一个文件,我是在桌面,新建test.py,如下:
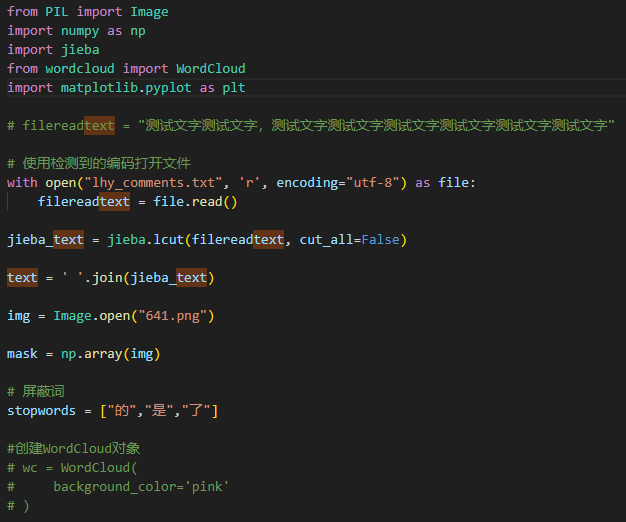
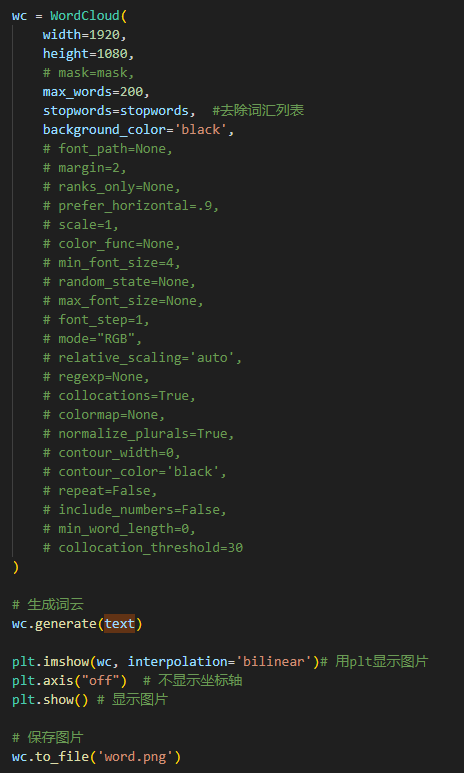
在命令行中运行python test.py即可生成对应的效果图
主要参数详细说明:
font_path:字体路径。在win10系统中字体文件夹为C:\Windows\Fonts
width:输出的画布高度宽度,默认为400像素
height:输出的画布高度,默认为200像素
prefer_horizontal:词语水平方向排版出现的频率,默认 0.9。设置词语垂直方向排版出现频率为 0.1
mask : 用于设置自定义画布的背景
scale : 按照比例进行放大画布,如设置为1.5,则长和宽都是原来画布的1.5倍
min_font_size :显示的最小的字体大小,默认为4font_step :字体步长,默认为1,如果步长大于1,会加快运算但是可能导致结果出现较大的误差
mode:模式,默认为’RGB’,当为’RGBA’时,如果背景颜色为None,则会得到透明的背景
max_words :要显示的词的最大个数,默认为200
stopwords :停用词,设置需要屏蔽的词,标点符号、语气词等,如果为空,则使用内置的STOPWORDS
background_color : 背景颜色,默认是black(黑色)
max_font_size :显示的最大的字体大小
relative_scaling :词频和字体大小的关联性
regexp : 使用正则表达式分隔输入的文本
collocations :是否包括两个词的搭配,默认是True
=============================我是分割线=============================


这个主要是WordCloud中mask参数控制的

https://cloud.tencent.com/developer/article/2321974
